Jagawana — Internet of Things in Depth
05 June 2021
Jagawana is a Wide Sensor Network System deployed in the forests to prevent Ilegal Logging. By using sensors to pick up voices in the forests, we could monitor what happened in the forest in real-time. We deployed a Machine Learning Model to process the sounds taken by the sensor, then the model will identify the sounds into various categories, such as chainsaws, trucks, gunshot, and burning sounds. We will be using Android App to monitor and notify the user if suspicious events were happening in the forest, the user could also be able to hear the sound itself to ensure the results are correct.
One of the keys to our project is how we will gather audio from the forest, our solution involves creating a Wide Sensor Network that spans across the forest. This idea is popularly used by many researchers, especially in detecting forest fires using a smoke detector.
Our idea is to deploy the sensor device along with microphones, battery, solar panel, SD card, and an RF transmitter. Ideally, the sensor device would be able to detect and record sounds, have a long long battery life, and communicate far away using an RF transmitter. This may sound complex and overwhelming, so many engineering fields are involved from programming, electronics, and also telemetry. Thus, we are trying to keep it simple and not go into the details soon.
The Device
The device itself has several specifications, first off it must have enough flash memory to transmit data and do simple filtering for sounds. The general option would be ESP32 and Teensy, both are powerful and cheap prototype microcontrollers and popularly used by many hobbyists. There is also the alternative to using Raspberry Pi, but the costs of material will jump out too much.
The device will be deployed in a remote location, which means the device needs to be sustainable. Our solution is by using a solar panel and a battery. We haven't started our research on this, so I will skip the details.
Our device will be the ears, listening to every sound inside the forest. We haven't found a suitable microphone module for the job, as the microphone is supposed to hear from distances (~100m — 1000m) to be efficient and cutting down the number of devices needed. Our prototyping model uses a generic microphone module such as MAX9814 (Analog) or INMP44 (I2S).
To prevent overloading the memory and transmission, we need a mechanism to prevent any sounds to trigger the device. We are proposing the idea to use the same mechanism as Amazon's Alexa and other home devices. Alexa didn't send any audio data to the cloud until the wake word is called. The way it works is by having Alexa listening all the time, storing a short audio data into the buffer memory, process it whether the wake word is called or not, if not then Alexa will record a short audio data again replacing the buffer memory. Using this mechanism, Alexa won't run out of data even if it listens to our conversation all day long.
The general idea would look like the flowchart below.

Diagram Flow of Passive Listening
Our first plan is to use a simple CNN model fitted into our device, we haven't researched that area yet so we proposed a plan B which is by analyzing the audio data and use the chainsaw frequency as the trigger. Chainsaw sounds dominate in frequency bands between 500 Hz and 8 kHz, by extracting the audio data into Mel Spectrogram, we could see the uniqueness of chainsaw sounds.
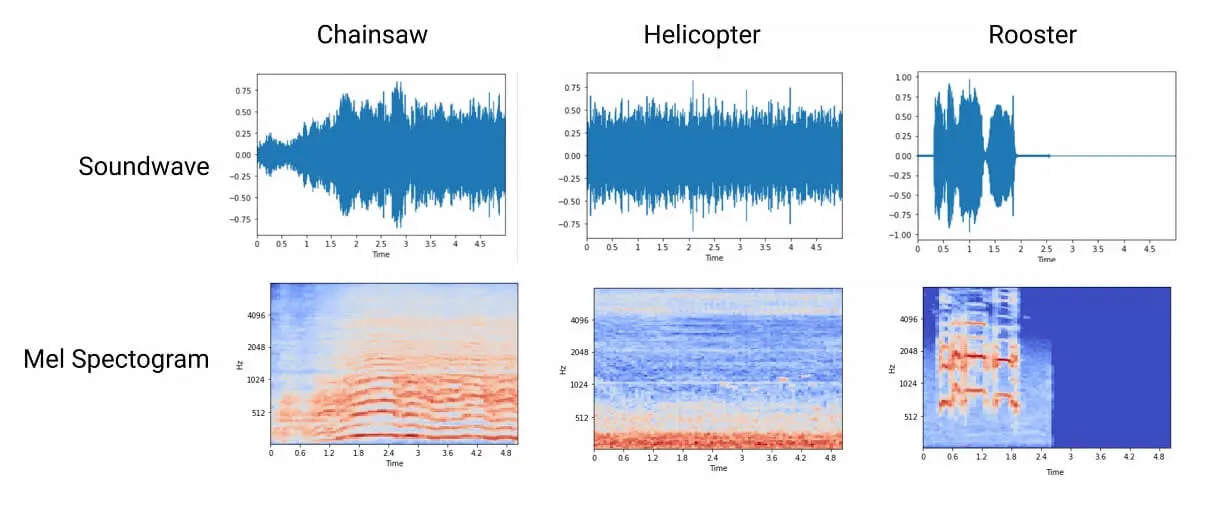
Comparison of Different Sounds
The Network
This is the hardest part of the system. In real-life situations, especially in rural areas like forests, there will be no cellular signal at all. To communicate with each other, we are going to use an RF transmitter especially looking at the LoRaWAN module. LoRa is communication technology, just like WiFi and Bluetooth, that specializes in long-range and low-power communication. Using LoRa, devices could communicate up to 2 kilometers through obstacles, and up to 20 km with a line of sight.
Creating a sensor network is not as simple as that, to cover a whole area with as few sensors as possible, there needs to be a network architecture that is effective and robust. Again, this topic is really heavy and discussed in many papers like this, this, and this one. We proposed a simple model to illustrate and simplify the detail, but the real-life deployment will need a more complex model to effectively be used.

Simple Illustration of Sensor Network
Current Progress
Limited by time and budget, on this 1 month project we decided to only develop our device in the home environment, using ESP32, MAX9814 microphone, and an SD card reader.
The device would communicate with mosquitto broker on my laptop using MQTT, and the laptop as the gateway will forward the audio data to Google Cloud Platform for further processing. I have documented the code on my Github repo here.
The requirement I set for our prototype board is :
- Record and Store audio data to .wav format in SD card
- Read the data and send it using MQTT
Record and Store Audio Data
First off, there are two kinds of microphone modules out there, the analog one like MAX9814, and the one with I2S support like INMP441. I bought the MAX9814 without doing research beforehand, but I would recommend you guys to try the one with I2S support.
Recording audio data is a challenge itself, but to store the audio data has a trick on it's own. There is a thing calledDMA which stands for Direct Memory Access, this will allow us to write the audio data directly to memory without any interference from the CPU. This will allow our program and CPU not to freeze due to saving data to memory. I was originally to program the ESP32 using Micropython, but the library I found only supports DMA and I2S, so me and my analog microphone can't use the library. After gone through testing and searching, I found this C++ library that do support analog microphone for DMA, and so I modified the code to communicate with my MQTT broker.
The code on the repo itself is quite explanatory, it has several configuration code to adjust the parameter like duration and sampling rate. I'm trying to adjust it to my dataset which is using 8-bit resolution and 16KHz sampling rate but the audio file got distorted, I'm still trying to figure out the solution.
Sending Data to MQTT
MQTT is a lightweight communication protocol, popularly used in microcontrollers. Here is a great article about MQTT. Using C++ and Arduino IDE, I'm using the most popular MQTT library out there from PubSubClient.
Although it's not intended to be, I'm going to send my audio data through MQTT for the sake of fast prototyping. Through my experiment, a 10-second audio data (44100Hz Sampling Rate) takes about 800 KB of memory. The PubSubClient has a maximum packet size of 256 bytes by default, there is just no way I could send the full data in one go. What I had to do is to read and send the audio data chunk by chunk, the data will go to a buffer variable and replaced by a new chunk and another.
I first started reading and sending a chunk of 64 bytes, the whole file takes 147-second with a total of 13782 packets sent. It takes too much time since the buffer size is too small, I ended up editing the library's maximum packet size, and change the buffer size to 512 bytes. The file is successfully sent in 23-second with a total of 1723 sent.
To receive the data properly on the other side, I had the ESP32 send status using MQTT to begin receiving and saving the data to a file. You can check the code on my repo link below.
Last Words
The prototype is still in the early stages, there are many things to improve or even hasn't started yet. This project really challenges me since I haven't worked with audio data before on a microcontroller. Formatting and saving data is a big challenge. Transmitting the audio data through WiFi is already troublesome enough, but doing the same thing on LoRa network will be even more challenging.
Please give suggestions if you have any tips to solve the unending problems on this project. I hope I can see the end of this project. Feel free to ask anything if you want to replicate this project.